本文最后更新于 4 年前,文中所描述的信息可能已发生改变。
需求背景
由于微信公众号文章的搜索功能实在是过于孱弱(只支持内容分词匹配+是否最近读过+排序方式),对于某些公众号内的文章需要进行更多的检索就只能自己动手了。
设计思路
总的计划是将文章的内容都爬取下来保存在自己的数据库中,后续需要按照任何条件检索都可以很方便的进行。
微信公众号的文章列表在电脑端都是要在微信内置浏览器内显示的,在外部浏览器强行打开就会提示:请在微信端打开。但是具体一篇文章却是可以在浏览器打开的。因此,获取到文章链接再爬取文章内容相对是比较容易做到的。难点在于如何获取到完整的公众号文章列表。
抓取文章列表请求
由于微信公众号主页不能在浏览器中打开,因此考虑使用抓包工具抓到请求文章列表的请求。 
Mac 上大家推荐的大多是 [Charles](https://xclient.info/s/charles.html)这款软件。不过这款软件在我的 mac 上好像有点水土不服,反正就是无法抓到任何请求。

然后就检索到了 windows 上常用的抓包软件 Fiddler 出了一个 Fiddler Everywhere,可以在 MacOS 上安装使用。于是使用了一下,效果拔群!而且软件还支持 http 请求调试(Postman 危),界面也是非常现代化很好看,推荐!
Fiddler 抓到的公众号文章列表请求:
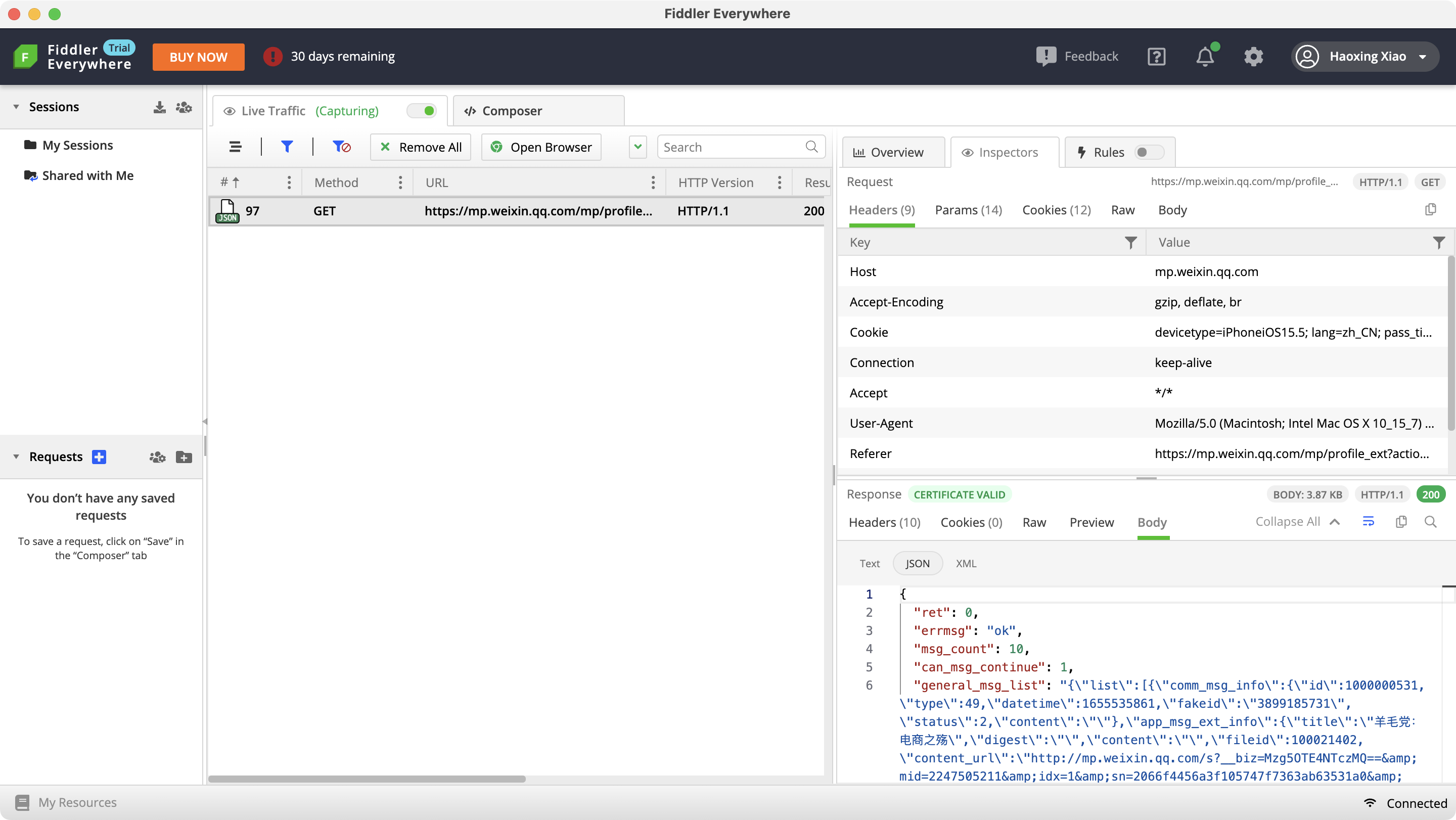
爬取文章列表
这一步具体操作就是用代码修改一些参数并重演上述的请求,将相应的结果拼接保存,从而获取整个公众号的所有文章链接~
将抓取的请求的 url、method、headers、params 都粘贴出来,放到 postman 里修改一下 offset 参数再次请求确认是可以正常执行的:
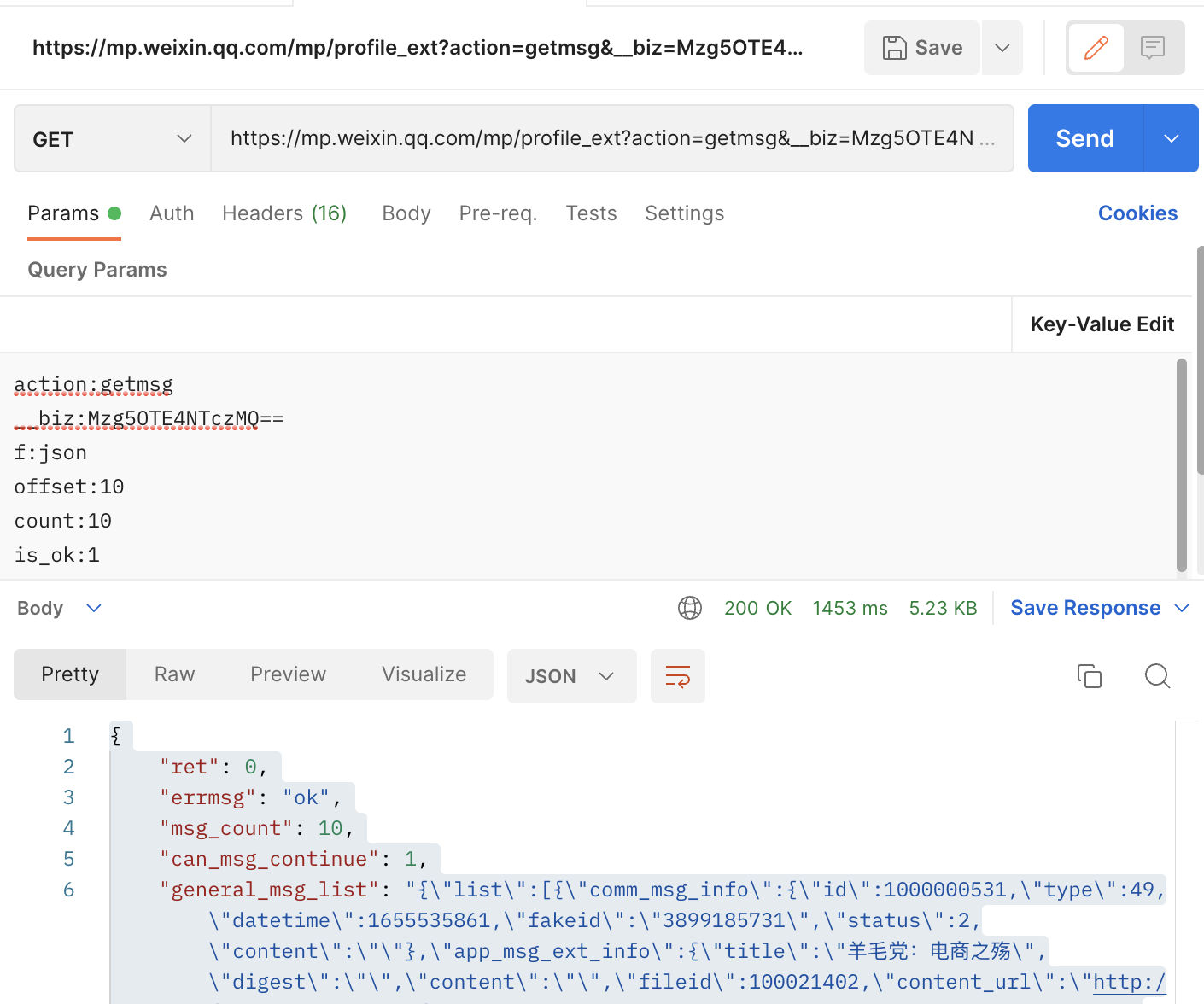
展开右边的代码,选择你想用的爬虫代码语言版本,我这里用了 python,编写完成后的爬取列表的代码如下:
import requests
import json
def send_req(offset):
url = "https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=Mzg5OTE4NTczMQ==&f=json&offset=" + str(
offset) + "&count=10&is_ok=1&...略"
payload = {}
headers = {
# 略
}
response = requests.request("GET", url, headers=headers, data=payload)
resp = json.loads(response.text)
return resp['general_msg_list'], resp['next_offset'], resp['can_msg_continue'] == 1
if __name__ == '__main__':
has_more = True
offset = 0
count = 1
all_list = []
while has_more:
msg_list, offset, has_more = send_req(offset)
print('第' + str(count) + '页:' + msg_list)
post_list = json.loads(msg_list)
all_list.extend(post_list)
count += 1
print(json.dumps(all_list))这里有一个小优化点:每次请求拿到的结果是{"list": […]},可以先展开再 append。这里懒得弄了就这样吧~后续解析的时候按行解析就行了。
爬取文章正文
获取到列表后观察一下结构:
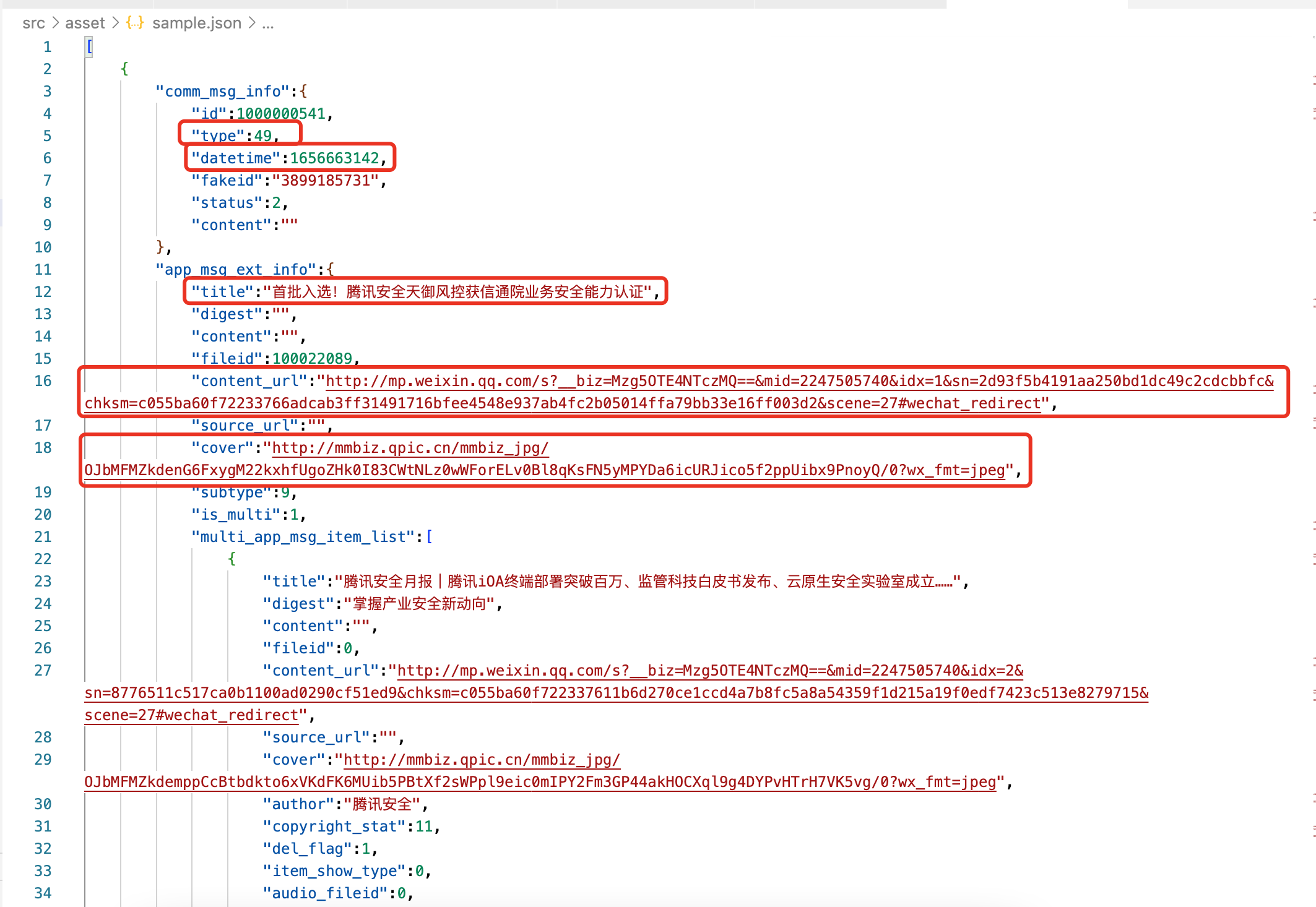
字段很多,按照自己需求决定将其中的 type(做分组检索可能用得上,虽然还没搞懂枚举值分别是什么含义),datetme(时间范围条件筛选),title,content_url,cover(封面图,后续展示效果优化时可能用得上)这几个字段挑选出来使用。
这里又有一个优化点,在最终展示的时候发现,有很多貌似草稿/已删除的也被查询出来了,这里应该要按照 status 做一次过滤。
将上述几个字段保存到结构体中,并留空 content 字段,等待后续爬正文内容再填充。
转换解析结构体
# Python 中面向对象的编程
class Record:
def __init__(self, obj):
common = obj['comm_msg_info']
ext = obj['app_msg_ext_info']
self.type = common['type']
self.datetime = common['datetime']
self.title = ext['title']
self.content_url = ext['content_url']
self.cover_url = ext['cover']
self.content = ''
with open('wechat.json') as f:
has_more = True
while has_more:
line = f.readline()
if line == '' or line == '\n':
has_more = False
continue
objs = json.loads(line)
arr = objs['list']
for obj in arr:
results.append(Record(obj))请求文章正文
读取了文章列表后就可以开始爬取文章数据了。这里用 requests 模块发送 http 请求获取正文,BeautifulSoup 模块解析响应的 html 文档。在 F12 控制台中可以检索到正文对应的文档树节点 id 为"js_content",用这个 selector 去获取元素及其文本即可。
counter = 0
fails = []
for record in results:
url = record.content_url
try:
resp = requests.get(url)
print('get success #' + str(counter))
except Exception:
print('get failed #' + str(counter))
fails.append(record)
counter += 1
content = resp.content
soup = BeautifulSoup(content, 'lxml')
text = soup.select('#js_content')[0].getText()
# 避免 csv 出错,统一改为中文逗号
text = text.replace(',', ',')
record.content = text
# TODO 标题也修改为中文逗号
record.title = record.title.replace(',', ',')写入 csv 文件
得到正文后需要保存落库。原本计划是写入数据库,但是看到 yunyoujun 的做菜项目使用了 csv 作为数据源,直接用 ts 代码读取数据而不用连接传统 sql 数据库,考虑到最近也正在看 react 的教程,于是决定也这么做!
# for export to csv
titles = ['title', 'datetime', 'content_url', 'content', 'type', 'cover_url']
f = open('database.csv', 'w')
with f:
writer = csv.DictWriter(f, fieldnames=titles)
writer.writeheader()
for row in results:
writer.writerow(row.__dict__)记录请求失败的case
由于网络等原因,正文获取总会有失败的可能性,这里在 request.get() 的时候记录下了对应的 url(上文的请求文章正文部分的fails.append(record)),最终会汇总输出到控制台,再根据情况考虑如何补上这部分数据。
if len(fails) > 0:
print('get ' + str(len(fails)) + 'failed:')
for fail in fails:
print(json.dumps(fail.__dict__))可能是微信公众号的服务比较不稳定或者是我网络不稳定,即使在浏览器中访问文章也有不小的概率失败,因此将请求加了重试,具体见下面的完整代码。
完整代码
import json
import requests
from bs4 import BeautifulSoup
import csv
class Record:
def __init__(self, obj):
common = obj['comm_msg_info']
ext = obj['app_msg_ext_info']
self.type = common['type']
self.datetime = common['datetime']
self.title = ext['title']
self.content_url = ext['content_url']
self.cover_url = ext['cover']
self.content = ''
# 加上重试
def try_get(url, times):
for time in range(times):
try:
resp = requests.get(url)
if resp.status_code != 200:
print('request failed for #' + str(time))
continue
return resp
except Exception:
print('request failed for #' + str(time))
continue
raise Exception('failed for ' + str(times) + ' times')
if __name__ == '__main__':
results = []
with open('wechat.json') as f:
has_more = True
while has_more:
line = f.readline()
if line == '' or line == '\n':
has_more = False
continue
objs = json.loads(line)
arr = objs['list']
for obj in arr:
results.append(Record(obj))
# for fetch content
counter = 0
fails = []
for record in results:
url = record.content_url
print(url)
try:
resp = try_get(url, 5)
print('get success #' + str(counter))
except Exception:
print('get failed #' + str(counter))
fails.append(record)
counter += 1
content = resp.content
soup = BeautifulSoup(content, 'lxml')
text = soup.select('#js_content')[0].getText()
# 避免 csv 出错,统一改为中文逗号
text = text.replace(',', ',')
record.content = text
# TODO 标题也修改为中文逗号
record.title = record.title.replace(',', ',')
# for export to csv
titles = ['title', 'datetime', 'content_url', 'content', 'type', 'cover_url']
f = open('database.csv', 'w')
with f:
writer = csv.DictWriter(f, fieldnames=titles)
writer.writeheader()
for row in results:
writer.writerow(row.__dict__)
if len(fails) > 0:
print('get ' + str(len(fails)) + 'failed:')
for fail in fails:
print(json.dumps(fail.__dict__))至此,爬虫部分的代码就完成啦。所有的公众号文章的内容都已经存入了 database.csv文件里了。后续就可以使用 react 项目去读取并展示了。
梳理文章数据
所有文章信息都导入到了 CSV 里了:

创建一个前端 React 项目:
npx create-react-app wechat-app然后进入项目 src 目录,参考 yunyoujun 的转换代码,将 csv 转换为 json 数据提供给 js 代码引用。
之所以转换的原因是前端代码只能 import 一个 json 文件而不能 import 一个 csv 文件。
转换代码:
# csvConverter.ts
import fs from 'fs'
import path from 'path'
import consola from 'consola'
const csvFile = path.resolve(__dirname, '../src/asset/database.csv')
const jsonFile = path.resolve(__dirname, '../src/asset/database.json')
function run() {
const csvData = fs.readFileSync(csvFile, 'utf-8')
let jsonData: Database = []
const lines = csvData.split(/\r?\n/)
lines.slice(1).forEach((line)=> {
if(line) {
const attrs = line.split(',')
jsonData.push({
title: attrs[0],
datetime: parseInt(attrs[1]),
content_url:attrs[2],
content:attrs[3],
type:parseInt(attrs[4]),
cover_url:attrs[5],
})
}
})
fs.writeFileSync(jsonFile, JSON.stringify(jsonData))
consola.success(`Generate file success: ${jsonFile}`)
}
run()
export interface Item {
title: string
datetime: number
content_url: string
content: string
type: number
cover_url: string
}
export type Database = Item[]在 package.json 文件中添加如下:
{
...
"scripts": {
...
+++ "convert": "tsx src/csvConverter.ts"
}
}在命令行中执行转换代码:
npm run convert执行完成后就可以看到出现了一个新文件:database.json。此时就可以在项目中直接引用该文件作为数据源啦。
输出展示
前端使用 import 引入数据文件:
import data from './asset/database.json'随后就可以按照 React 的正常开发方式读取数据写业务代码了~~(程序员最擅长写的表格视图)
完整代码:
import React from 'react'
import ReactDOM from 'react-dom/client'
import './index.css'
import data from './asset/database.json'
// 函数式组件
function Record(props) {
let record = props.record
let time = new Date(record.datetime)
//日期
var DD = String(time.getDate()).padStart(2, '0'); // 获取日
var MM = String(time.getMonth() + 1).padStart(2, '0'); //获取月份,1 月为 0
var yyyy = time.getFullYear(); // 获取年
// 时间
let hh = String(time.getHours()).padStart(2, '0'); //获取当前小时数(0-23)
let mm = String(time.getMinutes()).padStart(2, '0'); //获取当前分钟数(0-59)
let ss = String(time.getSeconds()).padStart(2, '0'); //获取当前秒数(0-59)
let timeformat = yyyy + '-' + MM + '-' + DD + ' ' + hh + ':' + mm + ':' + ss;
return (
<tr>
<td>{timeformat}</td>
<td><a href={record.content_url}>{record.title}</a></td>
<td>{record.content.length > 50?record.content.substring(0,50):record.content + '...'}</td>
</tr>
)
}
// 传统组件
class DataBase extends React.Component {
constructor(props) {
super(props)
this.state = {
data: data
}
}
render() {
let recordList = []
// 只展示 top 10 预览
for(var i = 0; i <10;i++) {
recordList.push(<Record record={this.state.data[i]}/>)
}
return (
<div>
<p>loaded {this.state.data.length} records</p>
<table >
<td>
<th>时间</th>
<th>标题</th>
<th>正文</th>
</td>
{recordList}
</table>
</div>
)
}
}
const root = ReactDOM.createRoot(document.getElementById("root"));
root.render(<DataBase />);总结
很久不写博客了,这次使用技术解决了一个实际问题,正好将博客重新营业起来~
由于要去攻读博士学位,后面内容可能会更偏向于一些科研。不过也说不准┓( ´∀` )┏。