本文最后更新于 6 年前,文中所描述的信息可能已发生改变。
1 业务背景
1.1 是什么样的业务场景
当前业务场景中存在这样的一种较为特殊的需求:订单流的处理过程中,包括了一些决策的节点。如:拆单、合单、分快递等。这些场景存在共同点:
规则数量相对多,用单纯的分支代码逻辑实现起来麻烦且不优雅
规则随时可能会调整,如果用硬编码实现则调整周期长,不能满足业务场景的要求;此外,硬编码导致每次调整都需要开发的支持,加重了开发的负担。
规则的输入输出相对固定:输入一些字段的值,输出一些固定值的结果。不用的场景适合用同一套系统去维护。
此前 PHP 版本的系统中实现了一套较为简单的规则配置系统,但是其不管是输入还是输出,都是直接丢给用户一个输入框直接输入全文,用户面对这样的一个空白页面其实根本不知道填写什么。 因此,这版的 Java 新系统需求是需要实现一个更易用、拓展性更强的一个规则配置中心。暂时给的场景是规则数量较少的合单规则——当前仅有3条明确的合单规则,需要先将这些规则正确配置到系统中。
1.2 初识 Drools
本来计划自行实现一个较为固定逻辑的字段读取、字段写入的一套对象处理流程:
// precode for params
RuleResult result = RuleParser.parse(ruleParams);
// postcode for result现在想想就能发现这种设计思路存在一些未考虑到的问题:
- 拓展性极差;该部分的配置完全依赖于当时的业务场景的需求,如果出现了新的需求,如需要调整后续的程序结构,则只能通过调整
post代码实现,虽然这样也能满足当场的需求,但对于后续新需求的支持能力不足,维护起来仍然较为吃力。 - 规则匹配部分的算子设计;该部分的代码可能能实现,但是需要耗费一定时间设计+实现+调试。而且这部分的实现实际上属于底层支持,开发系统应该秉持的原则应该是:能用现成的工具就不要自己发明轮子。因此,这部分代码属实不必要。
偶然的机会,跟小爱部门的小康同学聊了聊,他给我说他们部门刚好需要调研一个开源工具:Drools规则引擎。从而打开了新世界的大门。
2 技术原理
2.1什么是规则引擎
规则引擎是基于规则的专家系统的核心部分,主要由三部分组成:规则库(Knowledge base)+Working Memory(Fact base)+推理机(规则引擎),规则引擎根据既定事实和知识库按照一定的算法执行推理逻辑得到正确的结果。(Drools中文网)
2.2 Drools
Drools 是一个基于Charles Forgy’s的RETE算法的,易于访问企业策略、易于调整以及易于管理的开源业务规则引擎,符合业内标准,速度快、效率高。 业务分析师人员或审核人员可以利用它轻松查看业务规则,从而检验是否已编码的规则执行了所需的业务规则。(还是Drools中文网)
2.3 Drools特点
- 支持DSL语法、XML语法定义规则。
- 采用RETE算法
- 开源产品
- JBoss产品,成熟度高
2.4 就决定是你了
不管是从技术栈(Java)还是从产品的功能上来看,Drools规则引擎都完美符合我们当前的业务场景的需要,而后我们又调研了它的算子支持、结果语句的支持、动态加载的实现等多个方面的特性,最终敲定采用该方案实现我们的规则配置中心。
3 规则语法介绍
Drools采用特殊的DSL语法定义规则,因此需要先熟悉该部分的语法。
package com.sample.drools.rule
import java.util.Map;
function isZero(val) {
return val == 0;
}
rule "name"
no-loop true
when
$message:Message(status == 0)
then
System.out.println("fit");
$message.setStatus(1);
update($message);
end- imports:虽然是DSL,但是其基于
Java语法,因此同样需要用 Java 的 import 语句实现类的引用。 - functions:可以实现一些自定义函数,用在具体的规则中。由于使用 DSL 语法,在配置中心难以实现该部分代码校验,因此暂不实现该部分。
- rules:该部分是规则语法的重点,其中包括了rule声明行、参数行、条件(when)、结果(then)等部分,下面依次介绍。
- 声明行:rule + "name",一个规则的名称。
- 参数行:可以配置当前规则的参数,常见的有:no-loop, silience, agenda-group, auto-focus, activation-group, duration等,本项目用到了no-loop:是否重复执行当前规则,silience:优先级,activation-group:同组只会执行一条匹配的规则。
- 条件约束: 条件语句基本格式是:val:Object([field op value]*),一些例子:
// 一般约束
$c : Cheese( type == “stilton”, price < 10, age == “mature” )
// && 和 || 约束
Cheese( type == “stilton” && price < 10, age == “mature” )
Cheese( type == “stilton” || price < 10, age == “mature” )
// matches 操作
Cheese( type matches “(Buffalo)?/S*Mozerella” )
Cheese( type not matches “(Buffulo)?/S*Mozerella” )
// contains 操作
CheeseCounter( cheeses contains “stilton” )
CheeseCounter( cheeses not contains “cheddar” )
// memberof 操作
CheeseCounter( cheese memberof $matureCheeses )
CheeseCounter( cheese not memberof $matureCheeses )
// 字符串约束
Cheese( quantity == 5 )
Cheese( bestBefore < “27-Oct-2007” )
Cheese( type == “stilton” )
Cheese( smelly == true )
// 绑定变量约束
Person( likes : favouriteCheese )
Cheese( type == likes )
// 返回值约束
Person( girlAge : age, sex == “F” )
Person( age == ( girlAge + 2) ), sex == ‘M’ )
// 复合值约束
Person( $cheese : favouriteCheese )
Cheese( type in ( “stilton”, “cheddar”, $cheese )
// 多重约束
Person( age ( (> 30 && < 40) || (> 20 && < 25) ) )
Person( age > 30 && < 40 || location == “london” )
// 内联 eval 约束
Person( girlAge : age, sex = “F” )
Person( eval( girlAge == boyAge + 2 ), sex = ‘M’ )- 执行操作:这部分的代码虽然可以直接写
Java程序,但是应该简短,主要目的是插入和更新。
此外,还有
query等其他规则成分,由于复杂度的限制,项目中不会采用这些功能,这里也不做介绍。
4 将Drools应用到项目中
从上述的规则文件语法中可以看出,它的语法规则基于Java,是非常灵活的。但是本场景下需要将这部分的功能提供给业务方配置,因此过于灵活的配置方案不管是实现,还是交付使用成本都将会非常高,因此需要对规则进行一定程度的限制。
- 匹配的过程条件是多个对象、每个对象又有多个字段的判断,这部分的多次配置将会造成业务方一定困扰,因此这里我们简化为:传入一个对象,包括所有字段,业务仅选择字段和写对应每个字段的筛选条件即可。
- imports:我们默认导入java.util.Map和java.util.HashMap作为结果集的类型,以及入参的对象的引用。
- function 和 query:出于简化考虑暂不实现该部分的配置。
- rule参数配置:这里使用了部分需要的参数:
- salience:优先级,这个参数是提供给用户配置的,确认执行的顺序。
- activation-group:一个规则集中的规则都在同一个分组中,避免匹配完高优先级的规则后仍然进入低优先级的规则导致结果集字段被覆盖。
- no-loop:本是用于防止规则重复匹配,这里结果操作中没有update操作,因此也不会出现重复匹配,为了保险还是设置一下该参数。
- rule 条件配置:只提供一个条件对象和返回结果集合,用户能配置的部分为条件对象的字段的条件,条件间的关系暂定逗号分隔,都为且(&&)。
- rule 结果配置:可以直接写 Java 程序,但是为了保证业务方的使用体验,因此这部分做了极大的限制:只能向传入的Map中写入键值对。而且键也是由管理员配置的字段中选取,从而保证了业务方面的使用不会有太高的门槛。 综合以上的条件,我们可以得到我们项目中使用的规则文件的基本结构:
package com.sample.drools.rule
import java.util.Map
import java.util.HashMap
import com.sample.RuleCondition
rule "[ruleName]"
no-loop: true
salience: [priority]
activation-group: sample
when
$condition: Condition([f1] [op] [v1], [f2] [op] [v2])
$resultMap: HashMap()
then
$resultMap.put([key1], [value1])
$resultMap.put([key2], [value2])
...
end上述的代码,只有括号包含的值是用户配置的,而且大部分都为选项,最大程度降低了配置成本。但是为了保证健壮和灵活性,也需要将每个规则集的条件和结果定义交给更有经验的开发者配置,因此同样需要设计一个规则集和字段管理的管理员配置模块。
5 功能设计
功能设计上参考之前通用策略部分,实现了“管理员侧”和“用户侧”2部分的管理系统,具体功能如下图:
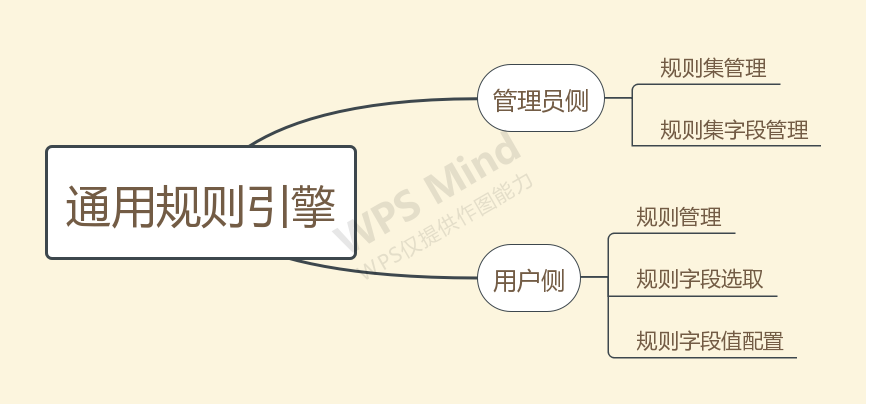
管理员侧可以创建规则集,对应着应用规则的不同场景,同时可以修改删除;还需要实现规则集内所有条件字段、结果字段的新增调整,以供用户侧选择。 用户侧可以选择一个规则集,添加新的规则,添加的时候要同时在所有字段中选择所需要的条件字段、结果字段,并设置好他们的操作符和值,确认当前规则的执行流程。用户同样可以修改、删除规则。 管理员在编辑规则集和规则集字段的时候有使用状态约束,在使用中的规则集和字段是无法删除的;用户在编辑规则和字段的时候有规则引擎校验约束,如果填写的规则导致校验失败,同样是无法配置的。
6 库表结构设计
原本计划用一套新库表结构实现该部分的数据存储,为了验证通用策略的拓展性,因此将通用规则部分的数据适配到通用策略的库表结构中。
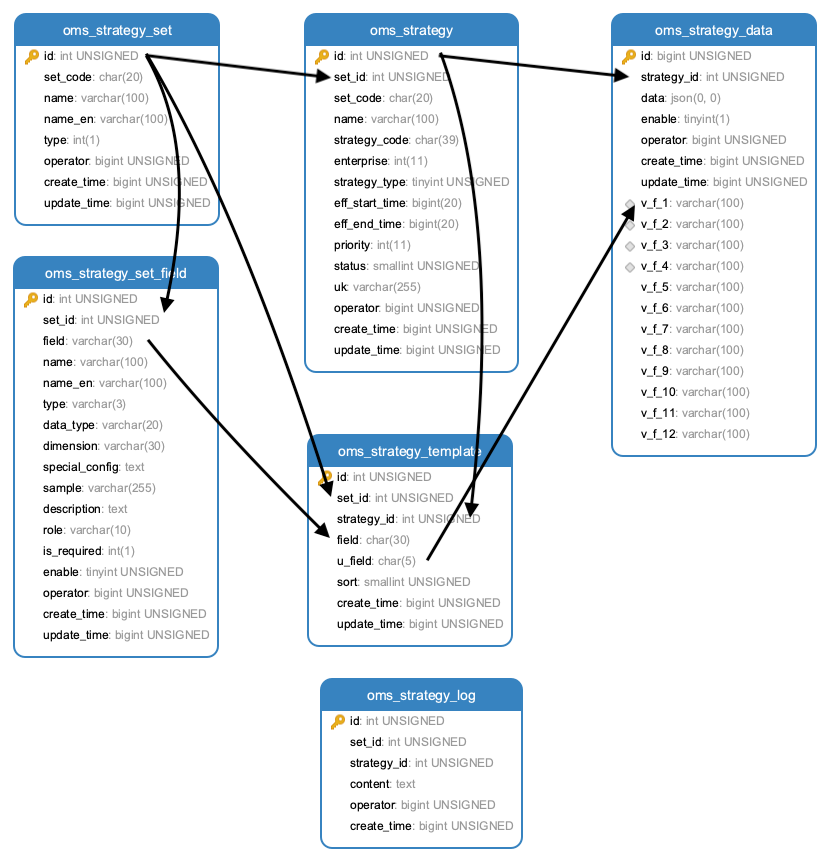
不过比较好的是,该库表结构只需要进行少量的拓展即可实现对规则部分的支持。
策略集字段增加角色信息字段(role),是否必填(isRequired)。
策略集表增加
type属性判断是规则还是策略。
规则文件和库表结构对应关系如下表:
| 规则文件字段 | 库表结构位置 |
|---|---|